I quite frequently stumble upon people in the Python community being misled to think that using async Python code will make their APIs “run faster”. Async Python is a great feature and should be used with care. One point that I constantly find being overseen is the mix of sync and async code. The general rule is that we should never mix blocking code with async code. I would like to present in this post a simplified example where we can observe the usage of async Python will hurt the performance of an API and then see how we can fix it.
Our example application is a FastAPI service that needs to call two operations from an external API within the handling of an HTTP request.
Those are all the dependencies we will use for the example:
# file requirements.txt
fastapi[all]==0.65.1
uvicorn[standard]==0.13.4
requests==2.25.1
httpx==0.18.2Let’s look at the example API code:
# file app/application.py
from fastapi import FastAPI
import requests
import uuid
import logging
logging.basicConfig(format="%(asctime)s %(message)s")
log = logging.getLogger("myapp")
log.setLevel(logging.DEBUG)
app = FastAPI()
EXTERNAL_API_ENDPOINT = "http://localhost:8888"
@app.get("/healthcheck")
async def healthcheck():
return {"status": "ok"}
#
# Async mixed with blocking
#
def internal_signing_op(op_num: int, request_id: str) -> None:
session = requests.Session()
response = session.request("GET", EXTERNAL_API_ENDPOINT, timeout=2000)
print(f"{request_id} {op_num}: {response}")
def sign_op1(request_id: str) -> None:
internal_signing_op(1, request_id)
def sign_op2(request_id: str) -> None:
internal_signing_op(2, request_id)
@app.get("/async-blocking")
async def root():
request_id = str(uuid.uuid4())
print(f"{request_id}: started processing")
sign_op1(request_id)
sign_op2(request_id)
print(f"{request_id}: finished!")
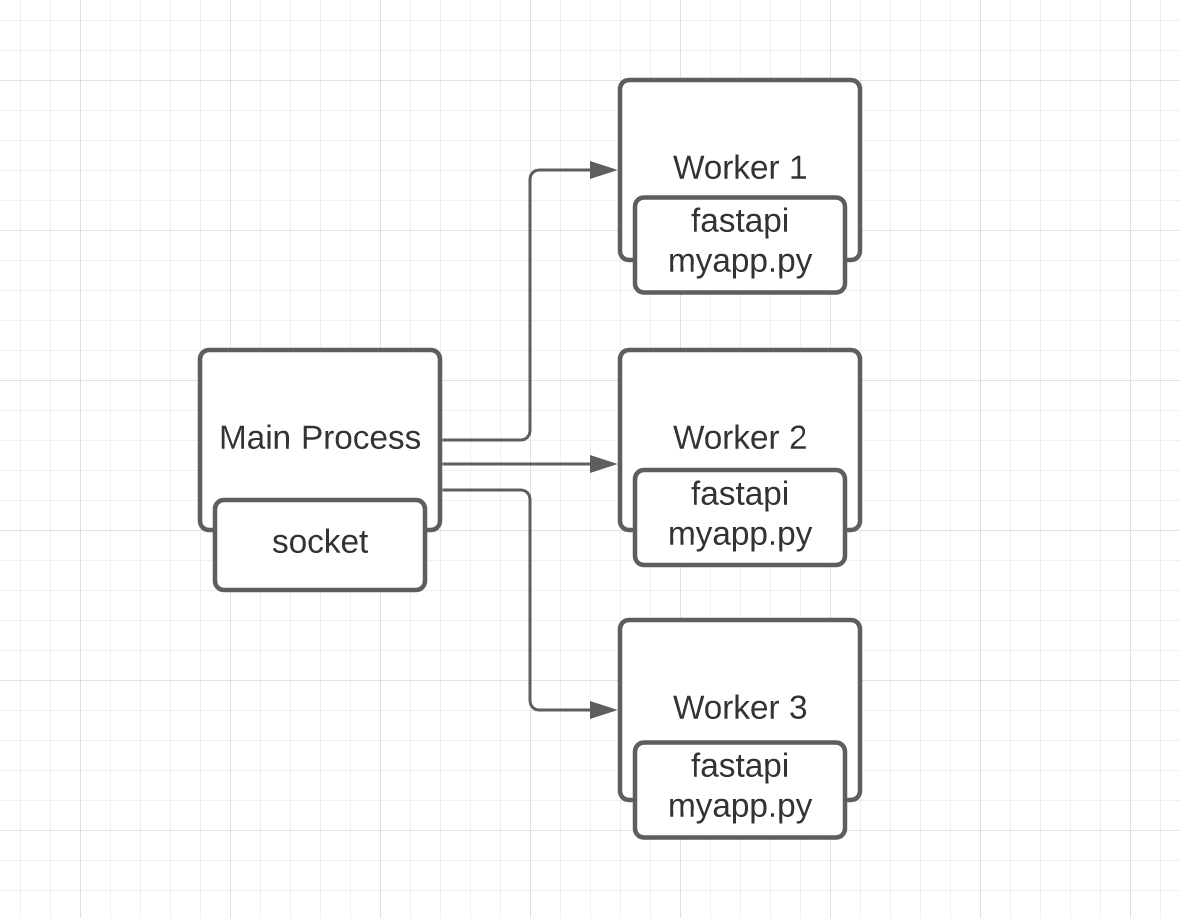
return {"message": "hello world"}Here we have a simple application that tries to replicate the behavior that I’m trying to point out. We have mixed async code with the synchronous library requests. The code works fine, but there is one problem. To understand the problem, we need to recap on how Uvicorn works. Uvicorn executes our application server by spawning workers (OS sub-process) that handles the requests coming into our server. Every worker (sub-process) is a fully-featured CPython instance and has its own I/O loop that runs our FastAPI application.
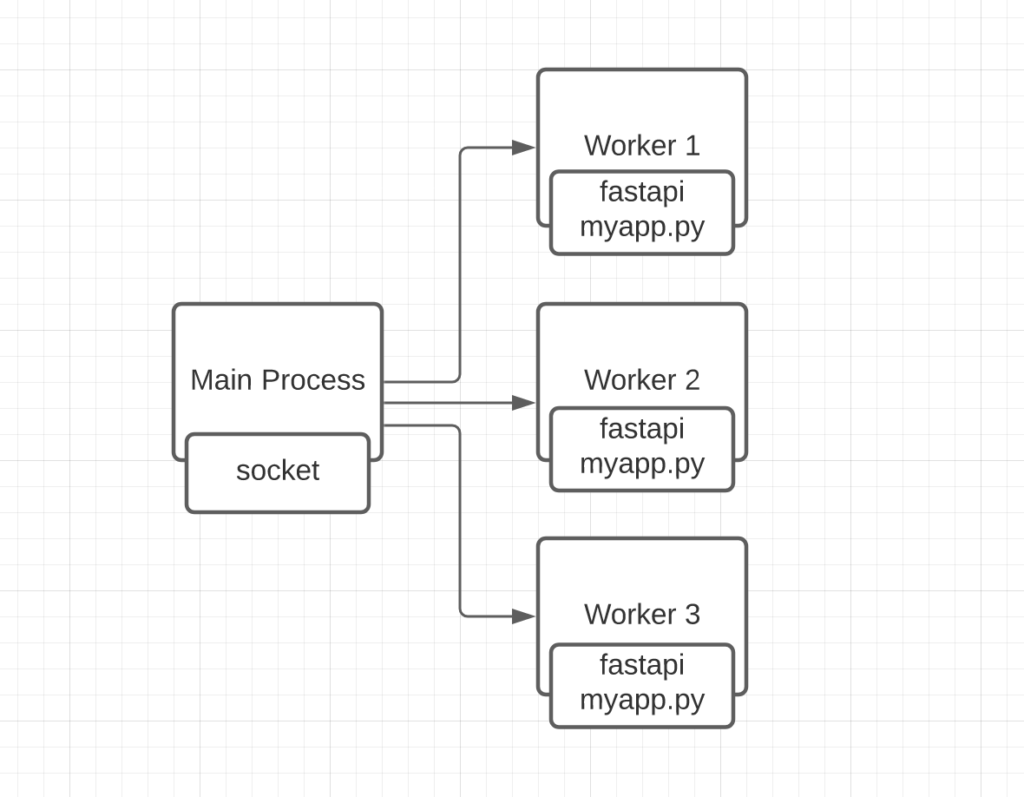
The Main Process holds a socket that is shared with the workers and accepts the HTTP requests that are handled by the workers to actually process the request. We can have as many workers as we want, usually the number of CPU cores. In our case, to make it easier to analyze the behavior, we are going to run only a single worker. We execute our server with the following command:
uvicorn app.application:app --workers 1I’ve set up a fake external API that we will use for this example. Just a simple server that takes a long time to execute some obscure operation (sleep(20) 😄 ).
# file external_api.py
import asyncio
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
await asyncio.sleep(20)
return {"message": "Hello World"}We spin up the external API server using this command:
uvicorn external_api:app --port 8888 --workers 1We set 1 worker here for no good reason, the important part here is to make the external API run in the port 8888 which is the one we’ve hardcoded in our example application.
Full working tree of the example for reference:
.
├── app
│ ├── __init__.py
│ └── application.py
├── external_api.py
└── requirements.txt
1 directory, 4 filesNow we can call our application with mixed async and sync code and observe what is printed out. I used httpie to make the requests. I’ve opened two consoles and made distinct HTTP requests to our application within the 20 seconds timeframe. This is the output:
❯ uvicorn app.application:app --workers 1 --log-level error
2021-07-07 20:08:57,962 9631c187-8f46-402a-b8ea-a15496643b81: started processing
2021-07-07 20:09:17,978 9631c187-8f46-402a-b8ea-a15496643b81 1: <Response [200]>
2021-07-07 20:09:37,987 9631c187-8f46-402a-b8ea-a15496643b81 2: <Response [200]>
2021-07-07 20:09:37,987 9631c187-8f46-402a-b8ea-a15496643b81: finished!
2021-07-07 20:09:37,988 694ee4be-a15a-49f6-ad60-7c140135a1f6: started processing
2021-07-07 20:09:57,997 694ee4be-a15a-49f6-ad60-7c140135a1f6 1: <Response [200]>
2021-07-07 20:10:18,004 694ee4be-a15a-49f6-ad60-7c140135a1f6 2: <Response [200]>
2021-07-07 20:10:18,004 694ee4be-a15a-49f6-ad60-7c140135a1f6: finished!As we can observe in the output that even though I’ve made both requests “in parallel” (same second) the server only accepted the request/started processing the second request (694ee4be-a15a-49f6-ad60-7c140135a1f6) after the full execution of the first request (9631c187-8f46-402a-b8ea-a15496643b81) which took a full 40 seconds. During the whole 40 seconds, there was no task switching and the worker event loop was completely blocked. All requests to the API are stale for the full 40 seconds, including requests to any other endpoints that might exist in other parts of the application. Even if the other requests don’t call the external API, they cannot execute because the worker event loop is blocked. If we call the GET /healthcheck endpoint it will not execute either.
One way to hide this problem and have our server still accepting multiple requests when the workers are blocked is to increase the number of workers. But those new workers can also be blocked on sync calls and our API is suspicious of a DDoS attack. The way to solve this problem is by not let our workers get blocked. Our API should be fully async. For that, we need to replace the requests library with a library that supports async.
Let’s now implement a “v2” version of our example API, still calling the same fake external API that takes 20 seconds to process. Furthermore, we will again run Uvicorn with a single worker.
Here is the code with the updated implementation:
#
# Async end-to-end
#
async def v2_internal_signing_op(op_num: int, request_id: str) -> None:
"""Calls external API endpoint and returns the response as a dict."""
async with httpx.AsyncClient() as session:
response = await session.request("GET", EXTERNAL_API_ENDPOINT, timeout=2000)
log.debug(f"{request_id} {op_num}: {response}")
async def v2_sign_op1(request_id: str) -> None:
await v2_internal_signing_op(1, request_id)
async def v2_sign_op2(request_id: str) -> None:
await v2_internal_signing_op(2, request_id)
@app.get("/all-async")
async def v2_root():
request_id = str(uuid.uuid4())
log.debug(f"{request_id}: started processing")
await v2_sign_op1(request_id)
await v2_sign_op2(request_id)
log.debug(f"{request_id}: finished!")
return {"message": "hello world"}Notice that I’ve replaced the requests library with the httpx library which supports async HTTP calls and has an API that is very similar to the one requests provide. The code is functionally equivalent to our previous mixed implementation, but now we implemented async fully. Let’s execute our API using the same commands as before.
uvicorn app.application:app --workers 1Then calling the API using httpie, but to the fully async endpoint:
http localhost:8000/all-asyncThe console output is:
2021-07-07 23:30:21,673 da97310b-1d20-4082-8f90-b2e163523b83: started processing
2021-07-07 23:30:23,768 291f556e-038d-4230-8b3b-8e8270383e62: started processing
2021-07-07 23:30:41,718 da97310b-1d20-4082-8f90-b2e163523b83 1: <Response [200 OK]>
2021-07-07 23:30:43,781 291f556e-038d-4230-8b3b-8e8270383e62 1: <Response [200 OK]>
2021-07-07 23:31:01,740 da97310b-1d20-4082-8f90-b2e163523b83 2: <Response [200 OK]>
2021-07-07 23:31:01,740 da97310b-1d20-4082-8f90-b2e163523b83: finished!
2021-07-07 23:31:03,801 291f556e-038d-4230-8b3b-8e8270383e62 2: <Response [200 OK]>
2021-07-07 23:31:03,801 291f556e-038d-4230-8b3b-8e8270383e62: finished!
We can observe in the output that both requests started processing immediately and they are still sequential in their own request lifecycle. The event loop of the Uvicorn worker is not blocked, that is why the second request could continue processing even though the external API did not finish its operation. Other requests, like the GET /healthcheck, are not impacted by the slow execution of the external API. Overall our application continues to serve other requests independently on the external API.
When using async Python one must be careful about what libraries to use. Even though a library might be very popular in the Python community, it doesn’t mean that the library will play well in an async application. Choosing the right libraries will make the execution of the application more concurrent by not blocking the I/O loop. The overall throughput of the application will be better as more unrelated requests can be processed by the same Uvicorn worker.
I’ve used async Python in some applications I maintain, and it was challenging to choose the right libraries to use. The team has to be on the watch for possible places in the code where the event loop may block. Even using the built-in Python logging library or a “print” statement is going to block the I/O loop. Usually, those blocking calls are negligible, but it is important to understand that they are there. I highly recommend also reading the official documentation on other tips for developing async code in Python. Have you developed an async Python API, what was your experience?